
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- Data Analysis
- SSO인증
- dns
- 색상코드
- AWS
- Network
- 날짜 함수
- tableau
- 맵차트
- 선형회귀
- Linear models
- SAML
- 클라우드
- map차트
- SSO
- SQL
- 태블로
- batch
- https
- 하드웨어
- 배치파일
- SSL
- SQL 테이블 삭제
- 테이블만들기
- 파이썬
- >>
- HTTP
- 방화벽
- MySQL
Archives
- Today
- Total
SeaForest
빅데이터를 지탱하는 기술 리뷰 (1) 본문
데이터 분야에서 너무 유명하기도 하고 추천도 받아서 이 책을 읽게 되었다. 데이터 엔지니어로 일을 하고 있는건 아니지만 데이터 엔지니어쪽 공부를 하고 싶다는 생각을 항상 하고 있었기에 이 책을 바로 읽게 되었다.

0. 들어가기 전
- 주제 : 자동화된 데이터 처리 ('데이터 활용 방법' 보다는 '데이터 처리 시스템화')
- 데이터를 이용하는 목적 (이 책에서는 2가지만 언급)
- 비즈니스 인텔리전스 : 기업의 업적 등을 수집해서 경영상의 의사결정에 도움
- 데이터 마이닝 : 통계 분석과 머신러닝 등의 알고리즘을 사용하여 데이터로부터 가치 있는 정보 발견
1. 빅데이터의 기초 지식
1-1. [배경] 빅데이터의 정착
- 빅데이터의 취급이 어려운 이유
- 데이터의 분석 방법을 모름
- 데이터 처리에 수고와 시간이 걸림
- Hadoop
- 다수의 컴퓨터에서 대량의 데이터를 처리하기 위한 시스템
- 방대한 데이터를 저장해둘 스토리지와 데이터를 순차적으로 처리할 수 있는 구조 필요 → 수백 대, 수천 대 단위의 컴퓨터가 이용되어야함 → 이걸 관리하는게 Hadoop
- 다수의 컴퓨터에서 대량의 데이터를 처리하기 위한 시스템

- NoSQL
- 빈번한 읽기, 쓰기 및 분산 처리가 강점
- 여러 곳의 서버에 데이터를 분산 저장해, 특정 서버에 장애가 발생했을 때도 데이터 유실 혹은 서비스 중지가 발생하지 않는다는게 강점
- 요약
- 빅데이터의 등장 → Hadoop으로 데이터웨어하우스의 부하를 줄임 → 이전에는 IT 부서가 상당한 노력을 구축해야 하는 매우 한정된 것이었는데, 요즘엔 작은 프로젝트 단위에서도 데이터웨어하우스 구축하여 자체적으로 데이터 분석 기반을 마련하는 경우가 많음 → 2012년부터 데이터 시각화 하는 방법으로 ‘데이터 디스커버리’가 인기를 끌게됨 (지금은 기술상의 제약이 없어서 누구나 대규모 데이터 분석 업무를 할 수 있기 때문)
1-2. 빅데이터 시대의 데이터 분석 기반
- 빅데이터 시대가 기존의 데이터 웨어하우스와 다른 점은 다수의 분산 시스템을 조합하여 확장성이 뛰어난 데이터 처리 구조를 만든다는 점
- 데이터 파이프라인
- 차례대로 전달해나가는 데이터로 구성된 시스템 (데이터 수집 ~ 워크플로우 관리)
- 데이터 수집
- 가게 포스기로 쌓이는 데이터, 스마트폰 등 모바일 앱으로 모여진 이벤트 데이터, 서버의 로그 파일, 키워드 검색 데이터 등이 각각 서로 다른 기술로 데이터를 전송하는걸로 데이터 수집이 시작됨
- 데이터 전송 방법
- 벌크(bulk) 형 : 이미 어딘가에 존재하는 데이터를 저장해 추출하는 방법
- 스트리밍(streaming) 형 : 차례차례로 생성되는 데이터를 끊임없이 계속해서 보내는 방법 (실시간 데이터 생각하기) >> 실시간으로 쌓이다 보니 대량의 데이터가 되고, 어느 정도 정리된 데이터를 효율적으로 가공하기 위한 배치처리 구조
- 데이터 웨어하우스 vs 데이터 레이크
-
- 데이터 웨어하우스 : 데이터 소스에서 장기 보존용으로 정리한 테이블
- 데이터 레이크 : 데이터 소스에서 수집한 로우 데이터를 그대로 보존
-
- 데이터 엔지니어와 데이터 분석가
- 데이터 엔지니어 : 시스템의 구축 및 운용, 자동화를 담당
- 데이터 분석가 : 데이터에서 가치 있는 정보 추출
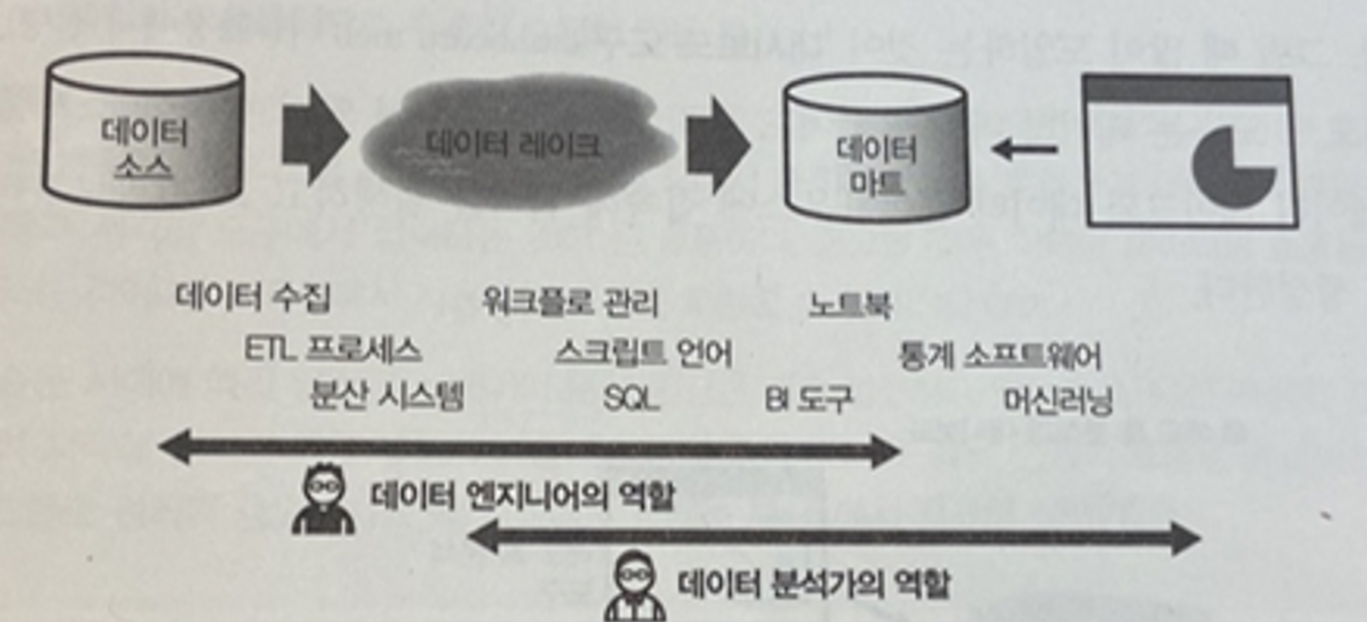
- 데이터를 수집하는 목적
- 데이터 검색
- 뚜렷한 목적이 없고, 언제 무엇이 필요할지 조차 모르기 때문에 모든 데이터를 취득
- 데이터 가공
- 목적이 명확하기 때문에, 필요한 데이터를 계획적으로 모아 데이터 파이프라인 설계
- (예) 추천 상품 제안, 충성 고객 파악 등
- 데이터 시각화
- 시행착오의 연속
- 확실한 해답이 없음
- 임의의 분석 환경을 갖추고, 여러 번 데이터 집계를 반복
- 시각화를 고속화하려면 데이터 마트 필요
- 집계 결과를 대시보드에 정리해서 계속 변화를 감시하고 싶을 때도 데이터 시각화는 필요
- 문제는, 항상 이상적인 데이터는 존재한다고 할 수 없는 점, 원하는 대로 집계 결과를 얻으려면 ‘시각화하기 쉬운 데이터’를 만들어야함
- 데이터 검색
- 확증적 데이터 분석과 탐색적 데이터 분석
- 확증적 데이터 분석 (confirmatory data analysis)
- 가설을 세우고 그것을 검증
- 통계학적 모델링에 의한 데이터 분석
- 탐색적 데이터 분석 (EDA, exploratory data analysis)
- 데이터를 보면서 그 의미를 읽어내려고 함
- 데이터를 시각화하여 사람의 힘으로 그 의미를 읽는 것
- 확증적 데이터 분석 (confirmatory data analysis)
1-3. [속성 학습] 스크립트 언어에 의한 특별 분석과 데이터 프레임
- 스크립트 언어
- 데이터 프레임
- 데이터를 집계하는 부분에서, 데이터 웨어하우스나 데이터 레이크를 이용하고, 그 결과를 데이터 프레임으로 변환하면, 데이터 확인 및 가공 가능
1-4. BI 도구와 모니터링
- 데이터에 근거한 의사 결정
- 자신의 행동을 결정할 때, 직감에 의지하는 것이 아니라 객관적인 데이터를 근거하여 판단하는 것
- KPI 를 자주 이용함
- BI 도구와 데이터 마트
- BI 도구에서 직접 데이터 소스에 접속하기
- 장점 : 시스템 구성이 간단
- 단점: BI 도구에서 지원하지 않는 데이터 소스에는 접속 불가능
- 데이터 마트를 준비하고, 그것을 BI 도구로부터 열기
- 장점 : 어떤 테이블이라도 자유롭게 만들 수 있음
- 단점 : 데이터 마트의 설치 및 운영에 시간이 걸림
- 웹 방식의 BI 도구를 도입하여 CSV 파일을 업로드 하기
- 장점 : 스크립트로 자유롭게 데이터를 가공할 수 있음
- 단점 : 데이터의 생성 및 업로드에 프로그래밍이 필요
- BI 도구에서 직접 데이터 소스에 접속하기
2. 빅데이터의 탐색
2-1. 크로스 집계의 기본
- 대량의 데이터를 크로스 집계하려면 SQL을 사용하여 데이터 집계(aggregation), 즉 sum()과 같은 집계함수(aggregate functions)를 이용해 데이터양 감소를 고려할 필요가 있음
- 데이터 집계 ▶ 데이터 마트 ▶ 시각화
- 데이터 마트 : 데이터 집계와 시각화 사이에 있는 것
- 데이터 집계와 시각화의 트레이드 오프(trade-off) - 55p
- ‘데이터 집계’에 최대한 많은 정보를 남기는 경우 : 데이터 마트가 무거워져서, 시각화 성능 떨어짐
- ‘데이터 집계’에 적은 정보를 남기는 경우 : 시각화 성능은 좋아지지만, 데이터 정보 부족으로 시각화 프로세스에서 할 수 있는게 적어짐
2-2. 열 지향 스토리지에 의한 고속화
- 대량의 데이터를 신속하게 처리하려면, 미리 데이터를 집계에 적합한 형태로 변환하는 과정 필요
- 수억개의 레코드를 가지고 있는 데이터 마트의 지연을 최소화하기 위해서는 데이터를 ‘열 지향의 스토리지 형식’으로 저장해야함
- MPP 데이터베이스
- 여러 디스크에 분산된 데이터가 서로 다른 CPU 코어에 의해 읽혀 부분적인 쿼리 실행이 이루어짐.
- 그 결과들은 한 곳에 모이고, 최종적인 결과가 출력됨
- 이러한 일련의 처리는 가능한 한 동시에 병렬로 실행
2-3. 애드 혹 분석과 시각화 도구
- 대시보드 도구와 BI 도구
- 대시보드 도구 : 새로운 그래프를 쉽게 추가할 수 있는 것이 중시됨
- BI 도구 : 대화형 데이터 탐색이 중시됨
- Redash
- 장점 : 즉각적인 대시보드 표시, 데이터 마트 필요 없음
- 단점 : 대량의 데이터 처리 불가, 그래프의 수만큼 쿼리를 실행해서 대시보드가 증가하면 백엔드 데이터 베이스 부하 증가
- Superset
- 데이터 마트가 있어야함
- 대화형 대시보드(interactive dashboard) 를 가정
- Kibana
- 자바스크립트로 만들어진 시각화 도구
- Elasticsearch 사용 필수
2-4. 데이터 마트의 기본 구조
- 스타 스키마
- 팩트 테이블을 중심으로 디멘전 테이블을 별 모양으로 결합된 형태
- 단순하고, 성능상의 이유로 데이터 마트에서 스타 스키마를 사용
'Data analysis' 카테고리의 다른 글
| 빅데이터를 지탱하는 기술 리뷰 (2) (0) | 2024.03.03 |
|---|---|
| 빅데이터 시대, 성과를 이끌어내는 데이터 문해력 리뷰 (0) | 2023.06.16 |
| [Data Analysis] Linear Models, 선형 회귀 모델 (0) | 2022.03.14 |
| [Data] 데이터 제공 사이트 리스트 (0) | 2022.01.01 |
'Data analysis' Related Articles
more


